
Gratis basis training kentekenherkenning
Wij hebben een basistraining kentekenherkenning voor u samengesteld uit de trainingen die ik afgelopen jaren heb gegeven. Ik hoop dat dit u inzicht geeft en zal leiden tot de correcte toepassing van een mooie techniek en veelgemaakte fouten kan voorkomen.
Wilt u meer informatie? Heeft u een probleem met uw huidige kentekensysteem? Wilt u een training bij u op locatie voor engineer en/of sales?
Neem contact met ons op via: info@parkingware.com
Gratis ebook kentekenherkenning: https://parkingware.nl/ebook/
Basis Training kentekenherkenning
Kentekenherkenning is een techniek die in basis bestaat uit twee technologieën: digitale camera’s en herkenningssoftware.
Wat is ‘het beste kentekenherkenningsysteem’?
Die vraag zal voor elke toepassing verschillend worden beantwoord maar komt in de basis neer op: een zo hoog mogelijke hitrate en een zo laag mogelijk foutpercentage.
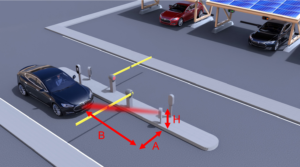
De standaard opstelling voor kentekenherkenning
Door Parkingware is er een bewuste keuze gemaakt om met kentekenterminals te werken die op het verkeerseiland worden gepositioneerd. De voornaamste reden is dat hiermee het aantal niet leesbare kentekens t.o.v. traditionele wand/plafond/mast bevestiging wordt gereduceerd. In dit document vindt u enkele praktijkvoorbeelden waaruit blijkt dat positionering aan wand/plafond tot een hoger foutpercentage zal leiden.
De definitie en berekening van hitrate en foutpercentage
Over de definitie en berekening van hitrate en foutpercentage bij kentekensystemen bestaan veel interpretatie verschillen. Veelal worden theoretische cijfers genoemd welke gebaseerd zijn op vaste uitgangspunten zoals ideale licht en weersomstandigheden, optimaal opgesteld standaard voertuig, etc. Wij zijn van mening dat dit een vertekend beeld geeft van de realiteit. Om een zo realistisch mogelijk beeld te geven adviseren wij een nulmeting te doen op locatie.
Hitrate
De hitrate bedraagt 99.99%. De hoge hitrate komt doordat er gekozen is om de triggering via de aanwezigheidslus (PDL: Presence Detection Loop) van het parkeersysteem te laten verlopen. Als de detectielus niet detecteert, vindt triggering via de ticketlezer plaats. De 0,01% uitval welke hier berekend wordt, is dus gebaseerd op het niet detecteren van een auto door de detectielus.
In de praktijk betekent een niet functionerende detectielus dat ook de inrijdterminal via de ticketlezer alsnog een hit kan genereren. Concreet is de hitrate van het KTH systeem dus eigenlijk 100%.
Praktijkomstandigheden die invloed hebben op de hitrate:
- Verkeerd uitlijning van de camera waardoor kentekens niet volledig in beeld komen;
- Verkeerde positionering (o.a. camera in de slagboom) waardoor kentekens niet volledig in beeld komen;

Een veel gemaakte fout in de opstelling van de kentekencamera is, de camera inbouwen in de slagboom
Foutpercentage
Om het foutpercentage zo laag mogelijk te houden zijn naast het gebruik van een goede kwaliteit camera, IR belichting en Engine een aantal andere praktische aspecten onderdeel van de kentekenoplossing zoals wij die bieden.
Praktijkomstandigheden die invloed hebben op het foutpercentage:
- Opstelling camera ten opzichte van het voertuig;
- Licht;
- Vuile en beschadigde kentekenplaat;
- Verschillende types voertuigen (hoog/laag);
- Verschillende posities van kentekenplaten.

De kentekencamera onder een normale hoek (links) en een te grote hoek (rechts)
Do’s and Don’ts
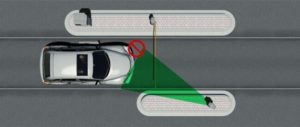
Kentekencamera foute positie aan rechterzijde van de rijbaan
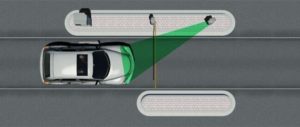
Kentekencamera aan de juiste zijde van de rijbaan

Een praktijkvoorbeeld waarbij de kentekencamera aan de verkeerde zijde van de rijbaan is gepositioneerd
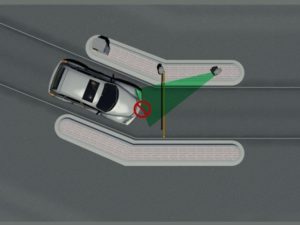
kentekencamera in bocht aan de verkeerde zijde van de rijbaan
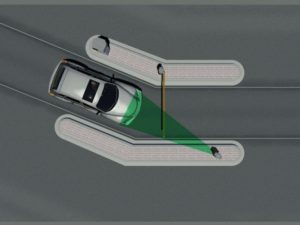
kentekencamera in bocht aan de verkeerde zijde van de rijbaan
De verschillende bewerkingsstappen van de herkenningssoftware
Het lokaliseren van de kentekenplaat

lokalisatie van de plaat door de kentekenherkenningsoftware
In de herkenningssoftware ondergaat het aangeleverde beeld een aantal voorbewerkingen. Om te beginnen wordt het kenteken in de digitale foto gelokaliseerd. De digitale foto bevat een deel van de voorkant van de auto en het kenteken staat daar ‘ergens’. De software is slim genoeg om te herkennen wat het kenteken is en wat de rest van de auto is.
De kentekenplaat rechttrekken

het rechttrekken van de plaat in de afbeelding door de kentekenherkenningsoftware
Vervolgens wordt de kentekenplaat ‘recht getrokken’. Vrijwel altijd is het kenteken onder een bepaalde hoek gefotografeerd, waardoor de rechthoekige vorm licht vertekend is tot een parallellogram of een trapezium. Hetzelfde wat je doet met een beamer om het beeld passend te maken op een rechthoekig projectiescherm, doet de software automatisch met de kentekenplaat. Het resultaat van deze bewerking is een rechthoekige afbeelding van de kentekenplaat.
Binairisatie

binairisatie van de kentekenafbeelding door de kentekenherkenningsoftware
De volgende stap wordt binairisatie genoemd. Dit betekent dat het beeld van de kentekenplaat van een foto in grijswaarden wordt omgezet in een beeld met alleen zwart en wit. Het is als de posters die Andy Warhol maakte in zeefdruk. Alle tussenliggende grijswaarden zijn verdwenen, het beeld bestaat allen nog maar uit zwarte letters, cijfers en tussenliggende streepjes op een witte achtergrond. De software is slim genoeg om hierbij de juiste grenswaarde te kiezen: welke grijstinten worden omgezet in zwart en welke in wit. Dat bepaalt uiteindelijk de herkenbaarheid van de karakters. Zeker bij vervuilde kentekens kan dit nog wel eens tot problemen leiden.
Segmentatie
segmentatie van de karakters in de kentekenplaatafbeelding door de kentekenherkenningsoftware
![]()
In deze stap wordt het kenteken opgedeeld in zijn verschillende karakters en tussenliggende scheidingstekens, zoals liggende streepjes. Bij deze stap maakt de software gebruik van verschillende logische technieken. Niet alleen worden de tekens gescheiden op basis van hun vorm, maar ook op basis van hun breedte. De software is uitgerust met de vormgegevens van kentekens uit alle mogelijke landen. In deze stap worden een aantal technieken gecombineerd om tot de juiste scheiding van de karakters te komen.
Herkenning
De laatste stap die de software maakt is de uiteindelijke herkenning van elk afzonderlijke karakter. Ook hierbij maken we gebruik van een combinatie van technieken. Wanneer er bijvoorbeeld twijfel is of een karakter een hoofdletter B of het cijfer 8 is, wordt bij de beoordeling ook de in de software ingebouwde kennis over mogelijke combinaties in de kentekens van een bepaald land betrokken. In Nederland kan een kenteken bijvoorbeeld niet met een 8 beginnen. Als de software op basis van andere vormkenmerken heeft vastgesteld dat het om een Nederlands kenteken gaat, zal de 8 of B op de eerste positie van het kenteken worden herkend als een B.
Output
Aan het eind van het herkenningsproces produceert de software de tekst van het kenteken plus een waarde die de betrouwbaarheid van de herkenning aangeeft. Deze gegevens worden vervolgens verwerkt door het systeem van de klant, bijvoorbeeld het Parkeer Management Systeem in een parkeergarage. Als de aangegeven betrouwbaarheid hoog genoeg is, zal het systeem het kenteken samen met het tijdstip van binnenkomen opslaan voor de duur van het verblijf van de auto in de garage. Bij traditionele parkeersystemen wordt het kenteken meestal op een ticket worden geprint.
Vervolgens opent het systeem de slagboom.

Parkingware slagboom opent automatisch met kentekenherkenning
Het hele proces dat we hierboven hebben beschreven speelt zich binnen 1 seconden af.
De klant die de parkeergarage inrijdt merkt geen vertraging ten opzichte van een parkeergarage zonder kentekenherkenning. Sterker nog: als de parkeergarage werkt met abonnementen en hij is abonnementhouder, hoeft hij geen ticket te trekken en gaat de slagboom sneller open dan in de traditionele situatie.
Bij het verlaten van de parkeergarage gebeurt het hele proces opnieuw, maar nu beschikt de software over belangrijke extra informatie. Het te herkennen kenteken kan alleen maar van een auto zijn die in het systeem geregistreerd staat en dus kan worden gematcht met de lijst in de garage aanwezige kentekens. Dit maakt het voor de herkenningssoftware gemakkelijker een herkenning met hoge betrouwbaarheid af te leveren. Het eindresultaat wordt doorgegeven aan het Parkeer Management Systeem, de slagboom wordt geopend en het systeem verwijdert de opgenomen beelden. De cyclus van een klantenbezoek aan de garage is voltooid.
Kwaliteit en betrouwbaarheid
Zolang de techniek van kentekenherkenning bestaat, is de vraag gesteld naar de kwaliteit van de herkenning. Maar in feite is de kwaliteit nog niet eens het belangrijkste. Stel dat de kwaliteit van je kentekenherkenning 95% zou zijn. Wat zegt dat dan? Dat zegt dat je van 5% van je herkenningsresultaten niet kunt garanderen dat ze correct zijn. Maar over welke 5% gaat dat? Elk resultaat dat het herkenningssysteem levert zou dan een kans van 5% hebben dat het niet klopt.
Bij Parkingware voorzien we daarom elk herkenningsresultaat van een betrouwbaarheidsgetal. Een betrouwbaarheidsgetal is een getal tussen 0 en 1000 dat aangeeft hoe betrouwbaar het is dat het herkende resultaat juist is. De herkenningssoftware die wij hebben ontwikkeld, gebruikt verschillende methodes van herkenning. De eerste methode die de kentekenbeelden analyseert, levert een resultaat af inclusief een betrouwbaarheidsgetal. Is het betrouwbaarheidsgetal boven de 800, dan wordt het resultaat als betrouwbaar beoordeeld en stuurt hij dit resultaat door naar het Parkeer Management Systeem. Is het betrouwbaarheidsgetal lager dan 800, dan stuurt de software het kentekenbeeld door naar een tweede herkenner, die volgens een andere methode werkt. Het systeem bevat bijvoorbeeld ook een herkenner die speciaal is getraind om vuile letters te herkennen. Ongeveer 4% van de kentekens wordt naar deze herkenner geleid.
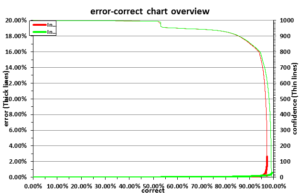
kwaliteitscontrole curve van de kentekenherkenningsoftware
Tot slot kan een onbetrouwbaar herkenningsresultaat gematched worden met een de vaste lijst van kentekens. Er kan een matchpercentage en het aantal karakter worden ingevoerd waardoor voor een goede match.